
Modern neural networks are often utilized to create so-called embeddings - abstract representations of data with impressive generalization properties, ready to use in downstream tasks. We consider such embeddings of a pre-trained model in a feasibility study of an identification tool for graphical signatures/doodles.
We know embeddings in modern ML provide an invaluable tool in both single-mode (visual, audio) and multi-modal applications (text-to-image, text-to-speech) as an initial stage. In this feasbility study, we leverage the similarity property - similar objects tend to align in the embedding space - to arrive at an identification tool.
In our case we consider visual signatures or doodles as a quasi-unique ID of a document or an item akin to a serial number. Is it possible to leverage embeddings to reach a reliable identification mechanism? Similarity property of embeddings is used in information retrieval tasks (an example of a vector database) where we look for SIMILAR documents, records or images. In our application, the key metric is precision or the decrease of false-positives - to reach reliability we would rather abstain from a decision than make a wrong one.
My tiny doodle dataset comprises of 44 hand-drawn, square-like doodles with eight 512x512 photos per doodle. Each with similar lighting, some small cropping and minor rotations. Below is a sample of this data:

First try, best try
As a first try, we test an off-the-shelf (pre-trained Vision Transformer network)[https://huggingface.co/timm/ViT-B-16-SigLIP-512] to create the embeddings (aka embedding vectors).
Once the images are parsed into embeddings, we prepare the ground truth similarity matrix with elements equal to one if the corresponding images depict the same doodle and zero otherwise. The pre-calculated embedding vectors are used in the cosine similarity matrix.
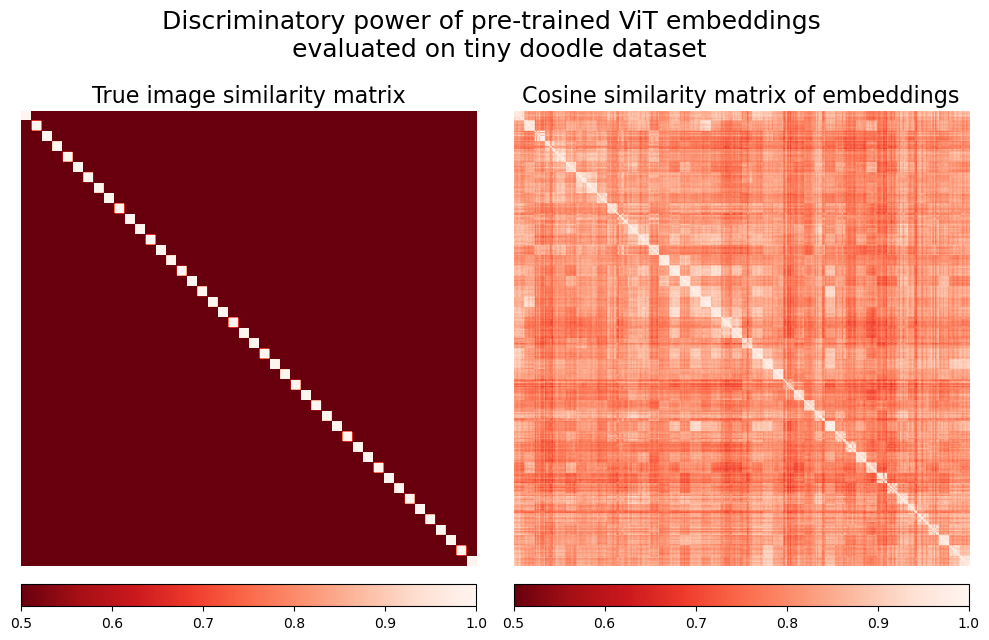
Both matrices vary between 0 and 1 - the structure of the true similarity matrix is clearly visible in the embedding-based matrix. Still, to assess the embeddings in a systematic way, we should pick a single similarity threshold value and measure the resulting discriminatory power and the number of misidentifciation errors. To this end, we prepare a precision-recall curve for a binary classification task of identifying whether two embeddings correspond to the same doodle or not.
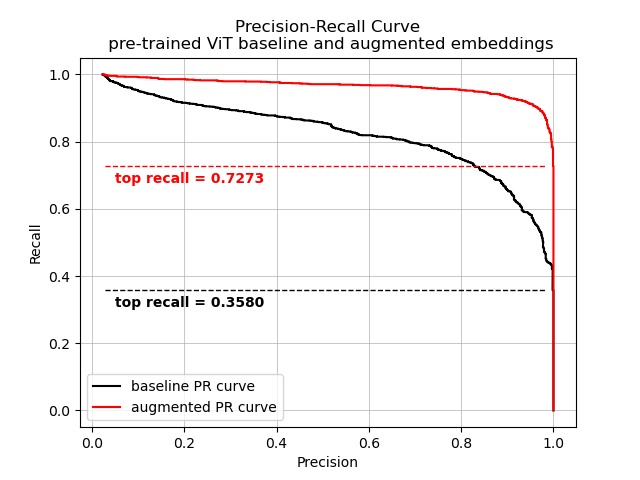
As argued before, for the ML model to serve as a good signature checker, we aim at a perfect precision = 1.0. The black precision-recall curve shows that the maximum recall for that precision is only 0.36 - to reach the ambitious goal of no mistakes, we’re missing a lot of opportunities for good identification.
How to improve on this? We first introduce a simple embedding augmentation technique. Instead of calculating a single embedding per image, we transform the image by four 90-degree rotations, calculate their embeddings and return the mean. This simple modification is reported as a red PR curve and gives a much better recall 0.73. Cool, can we improve it further?
How about grouped embeddings?
Another idea goes in a similar direction - we prepared the tiny doodle dataset so that each doodle has 8 images. What about leveraging the fact that we KNOW that multiple images belong to the same doodle? For a single pair of doodles, instead of looking at 8 * 8 = 64 independent embedding similarity checks, we group the embeddings together, calculate a bunch of between-group cosine similarities and take the mean. In that way, we are ensuring the comparison is more robust to single-embedding fluctuations.
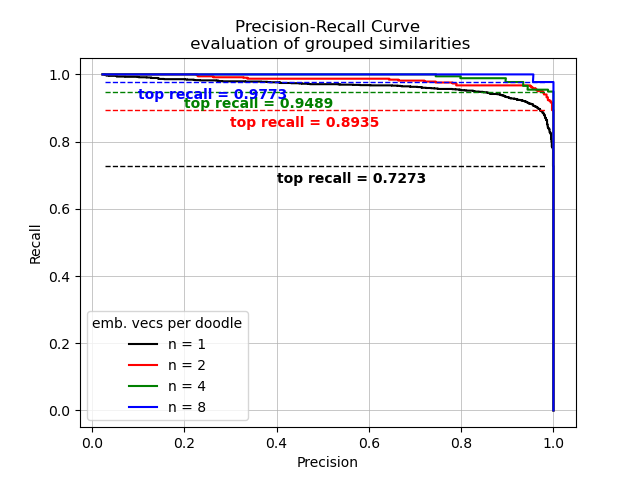
This method reaches a decent recall = 0.98 for a group of 8 images/embeddings per doodle. Cool!
Limitations
This approach has an obvious limitation - in general, a better recall is reached for an increasing number of embeddings. A custom tiny doodle dataset was prepared in similar light conditions, all photos have decent quality, there’s no motion blur etc.
Following such considerations, we lastly report the performance of embeddings as similarity measures evaluated on a tiny doodle dataset v2 with the same doodles but overall worse quality - variable light conditions, motion- and focal-blur.
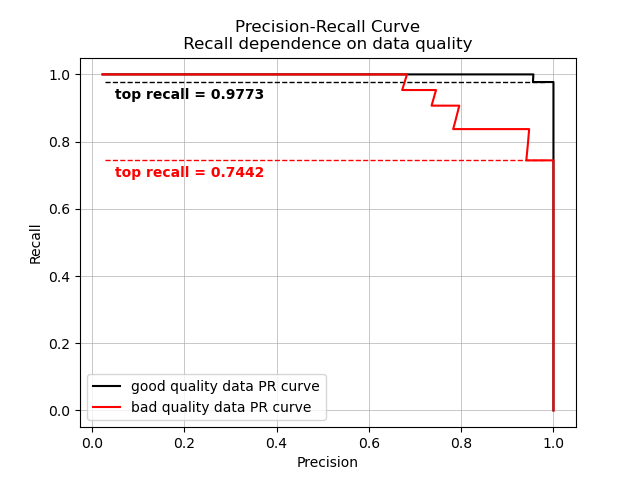
As expected, introduction of bad quality data leads to a drop in recall. In the end, data quality is important as well as increasing the number of embeddings.
Conclusions and next steps
- Out-of-the-box ML model offer embeddings vectors with limited discriminatory power for high-precision applications like signature identifcation.
- A simple augmentation of images and grouping of embedding vectors provide good improvement of the ML-based signature identification method at the expense of both computational time and user effort in gathering several images of the doodle/signature.
- As a next step, consider other pre-trained models.
- Development of a dedicated vector database.